一 、x265编码流水线与NALU生成概述
x265作为当今最先进的开源HEVC/H.265编码器,其NALU(Network Abstraction Layer Unit)序列化处理过程是将编码后的视频数据转换为标准网络传输格式的关键环节。本文将深入分析x265编码器内部如何将编码数据封装为符合HEVC标准的NALU单元。
- h265编码流程(原始数据到最终码流的封装过程)
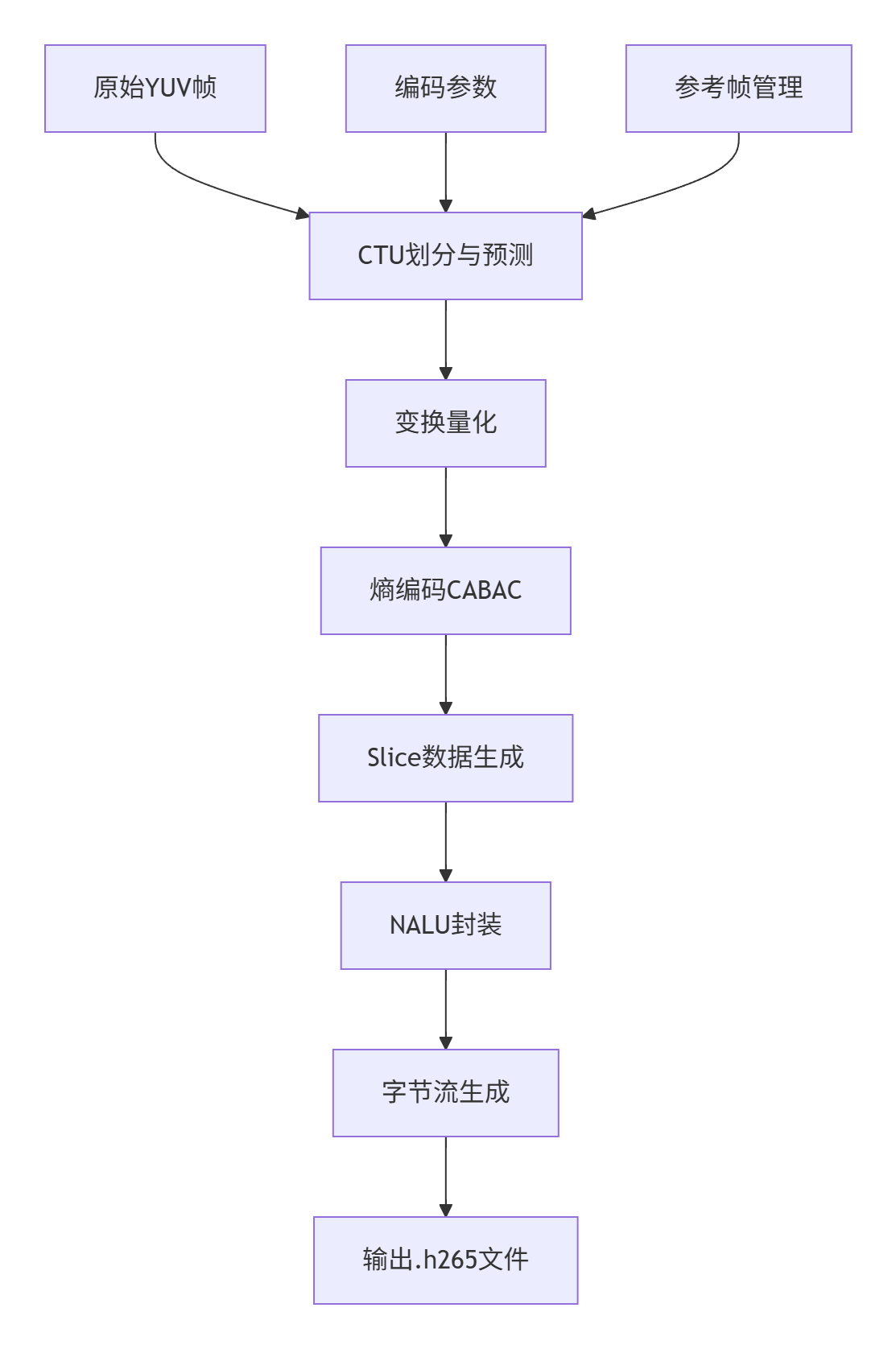

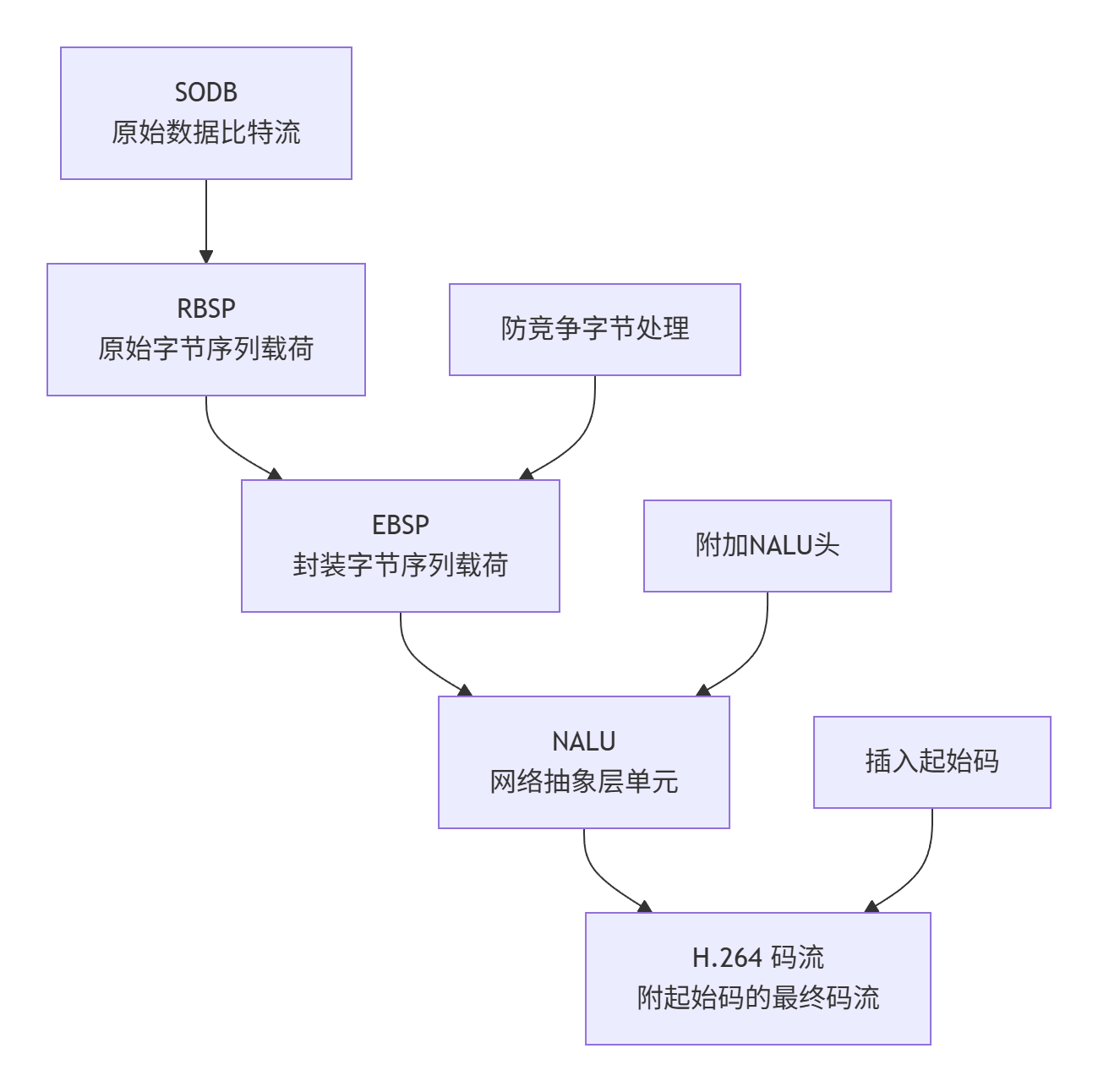
- H264编码流程(原始数据到最终码流的封装过程)
二 、HEVC NALU头部结构解析
HEVC的NALU头结构与H.264有显著不同,采用了两字节头部设计:
0 1 2
0 1 2 3 4 5 6 7 0 1 2 3 4 5 6 7 0 1 2 3 4 5 6 7
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|F| Type | LayerID | TID | Start Code |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+字段详解:
- F (Forbidden Zero Bit): 1位,必须为0
- Type: 6位,NALU类型(VPS/SPS/PPS/Slice等)
- LayerID: 6位,层次标识(用于可伸缩编码)
- TID: 3位,时域层次标识
码流结构,以及NALU内部的详细构成
-
需要注意的是,起始码并不属于其标记的NALU单元的一部分,它只是一个分隔符
| 0x00000001 | NALU Header (1 Byte) | RBSP Payload ... | 0x00000001 | Next NALU ... | |------------|----------------------|------------------|------------|---------------| | 起始码 | 单元头 | 有效载荷数据 | 起始码 | 下一个单元 | -
防竞争机制:避免混淆
也就是说,如果NALU的有效载荷数据中,恰好出现了连续的字节序列 0x000001或 0x00000001怎么办?解码器会误以为这是一个新的NALU的开始,导致解析错误,为了解决这个问题,视频编码标准引入了防竞争机制。在生成最终码流前,编码器会扫描数据,当发现可能被误读的序列(如 0x000000、0x000001、0x000002、0x000003)时,会在其中插入一个特殊的防竞争字节0x03;具体规则如下:原始序列 插入防竞争字节后 |------------|----------------------| 0x000000 0x00000300 |------------|----------------------| 0x000001 0x00000301 |------------|----------------------| 0x000002 0x00000302 |------------|----------------------| 0x000003 0x00000303 |------------|----------------------|相应的,解码器在解析NALU内部数据时,需要移除这些插入的 0x03字节,以恢复原始数据。
-
RTP中的起始码错误恢复
RTP封装H.264/H.265流时,起始码提供包丢失后的快速重同步:
RTP分片模式下的恢复策略:
(1) 单NALU模式:丢失即丢弃,起始码重新同步
(2) 分片单元模式:丢失关键分片则丢弃整个NALU
(3) 关键帧保护:I帧分片优先重传,结合起始码快速恢复 -
起始码与替代方案:AVCC格式
虽然起始码(这种格式常被称为 Annex B)很常见,但它并非唯一的NALU组织方式。另一种常见格式是 AVCC(或称 长度前缀 格式);差异如下: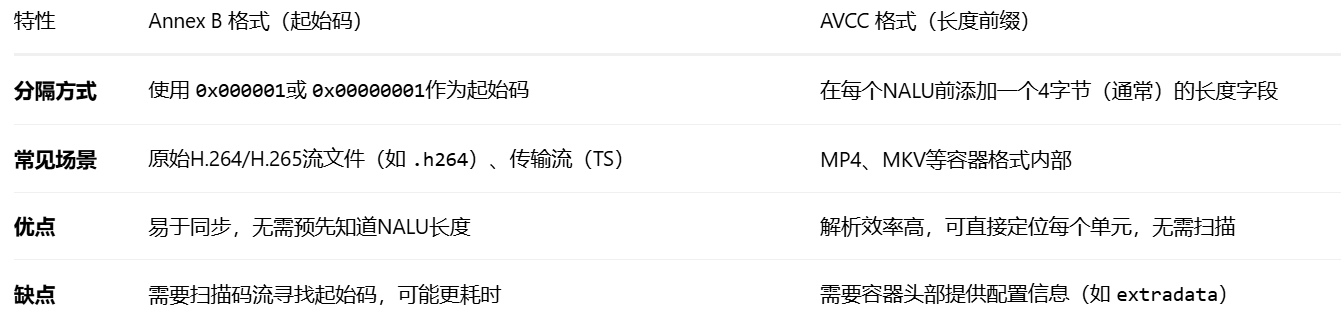
三、 H264高效 Annex B NALU 解析函数实现
#include <stdint.h>
#include <string.h>
typedef struct {
int startcodeprefix_len; // 起始码长度(3或4字节)
unsigned len; // NALU长度(不包括起始码)
unsigned max_size; // NALU缓冲区大小(由调用者设置)
int forbidden_bit; // 禁止位(应为0)
int nal_reference_idc; // NAL重要性(0-3)
int nal_unit_type; // NAL单元类型(1-31)
unsigned char *buf; // NALU数据指针(不包括起始码)
unsigned short lost_packets; // 丢包标记(默认为0)
} NALU_t;
// 检查3字节起始码:0x000001
static inline int find_start_code2(const unsigned char *data) {
return (data[0] == 0 && data[1] == 0 && data[2] == 1);
}
// 检查4字节起始码:0x00000001
static inline int find_start_code3(const unsigned char *data) {
return (data[0] == 0 && data[1] == 0 && data[2] == 0 && data[3] == 1);
}
/**
* 从H.26x Annex B格式的字节流中提取一个NALU(网络抽象层单元)
*
* @param frame 输入字节流(H.264 Annex B格式)
* @param length 输入流长度(字节数)
* @param nalu 输出NALU结构体(需要预先分配内存)
* @return 下一个NALU的起始位置(字节偏移),如果出错返回-1
*/
int get_annexb_nalu(unsigned char *frame, int length, NALU_t *nalu)
{
int info2, info3; // 用于存储起始码检查结果
int pos = 0; // 当前扫描位置
int StartCodeFound; // 是否找到起始码标志
int rewind; // 回退量(用于定位下一个NALU起始位置)
// 步骤1:初始化起始码前缀长度为3字节(0x000001)
nalu->startcodeprefix_len = 3;
// 步骤2:检查当前起始位置是否是3字节起始码(0x000001)
info2 = find_start_code2(frame);
if (info2 != 1) // 如果不是3字节起始码
{
// 步骤3:检查是否是4字节起始码(0x00000001)
info3 = find_start_code3(frame);
if (info3 != 1) // 如果也不是4字节起始码
{
return -1; // 没有找到有效的起始码,返回错误
}
else // 找到4字节起始码
{
pos = 4; // 跳过4字节起始码
nalu->startcodeprefix_len = 4; // 设置起始码长度为4字节
}
}
else // 找到3字节起始码
{
pos = 3; // 跳过3字节起始码
nalu->startcodeprefix_len = 3; // 设置起始码长度为3字节
}
// 步骤4:搜索下一个起始码(当前NALU的结束位置)
StartCodeFound = 0; // 初始化未找到标志
info2 = 0;
info3 = 0;
// 循环查找下一个起始码
while (!StartCodeFound)
{
// 步骤5:检查是否到达数据末尾
if (pos > length) // 已超出数据长度
{
// 处理数据末尾情况(最后一个NALU)
nalu->len = (pos - 1) - nalu->startcodeprefix_len; // 计算NALU长度
// 设置NALU数据指针(跳过起始码)
nalu->buf = &frame[nalu->startcodeprefix_len];
// 解析NALU头部信息(第一个字节)
nalu->forbidden_bit = nalu->buf[0] & 0x80; // 提取禁止位(最高位)
nalu->nal_reference_idc = nalu->buf[0] & 0x60; // 提取参考级别(第6-7位)
nalu->nal_unit_type = (nalu->buf[0]) & 0x1f; // 提取NALU类型(低5位)
return pos - 1; // 返回当前位置(数据末尾)
}
// 步骤6:向前扫描一个字节
pos++;
// 步骤7:检查当前位置是否是4字节起始码(0x00000001)
// 注意:检查的是从pos-4开始的4个字节
info3 = find_start_code3(&frame[pos - 4]);
// 如果不是4字节起始码
if (info3 != 1)
// 检查是否是3字节起始码(0x000001)
info2 = find_start_code2(&frame[pos - 3]);
// 如果找到任一类型的起始码,设置标志
StartCodeFound = (info2 == 1 || info3 == 1);
}
// 步骤8:计算回退量(找到起始码后需要回退的位置)
// 如果是4字节起始码,回退4字节;如果是3字节,回退3字节
rewind = (info3 == 1) ? -4 : -3;
// 步骤9:计算当前NALU的长度
// 公式:当前位置 + 回退量 - 起始码长度
nalu->len = (pos + rewind) - nalu->startcodeprefix_len;
// 步骤10:设置NALU数据指针(跳过起始码)
nalu->buf = &frame[nalu->startcodeprefix_len];
// 步骤11:解析NALU头部信息(第一个字节)
nalu->forbidden_bit = nalu->buf[0] & 0x80; // 提取禁止位(最高位)
nalu->nal_reference_idc = nalu->buf[0] & 0x60; // 提取参考级别(第6-7位)
nalu->nal_unit_type = (nalu->buf[0]) & 0x1f; // 提取NALU类型(低5位)
// 步骤12:返回下一个NALU的起始位置
return (pos + rewind);
}测试及验证
#include <stdio.h>
#include <stdlib.h>
int main() {
// 示例H.264数据(包含两个NALU)
unsigned char data[] = {
// 第一个NALU (SPS)
0x00, 0x00, 0x00, 0x01, // 4字节起始码
0x67, 0x42, 0x80, 0x0A, 0xDA, // SPS数据
// 第二个NALU (PPS)
0x00, 0x00, 0x01, // 3字节起始码
0x68, 0xCE, 0x38, 0x80 // PPS数据
};
int length = sizeof(data);
int pos = 0;
while (pos < length && pos != -1) {
// 初始化NALU结构
NALU_t nalu = {
.max_size = 1024, // 设置最大缓冲区大小
.lost_packets = 0
};
int ret = get_annexb_nalu(data + pos, length - pos, &nalu);
if (ret == -1) {
if (nalu.lost_packets) {
printf("Packet loss detected at position %d\n", pos);
} else {
printf("Error parsing NALU at position %d\n", pos);
}
break;
}
printf("Found NALU at pos %d:\n", pos);
printf(" Startcode len: %d\n", nalu.startcodeprefix_len);
printf(" NALU len: %d\n", nalu.len);
printf(" Forbidden bit: %d\n", nalu.forbidden_bit);
printf(" NAL ref idc: %d\n", nalu.nal_reference_idc);
printf(" NAL unit type: %d\n", nalu.nal_unit_type);
printf(" Lost packets: %d\n", nalu.lost_packets);
// 处理NALU数据
if (nalu.nal_unit_type == 7) { // SPS
printf(" SPS detected\n");
} else if (nalu.nal_unit_type == 8) { // PPS
printf(" PPS detected\n");
}
// 移动到下一个NALU
pos += ret;
}
return 0;
}版权声明
内容来源及使用限制
欢迎访问 TomgZHE研习社(网址:https://blog.tomgzhe.com)。本网站部分文章内容源自网络,仅作学习交流与参考分享;若您发现有内容涉嫌侵权,请立即联系 tomgzhe@qq.com,我们将在接到通知后的 48 小时内核实并删除相关侵权内容。
软件资源相关规定
本网站为个人非盈利性质的站点,所有软件资源均来自网络。这些资源仅用于个人学习、研究和参考,严禁用于任何商业用途。您下载和使用本网站软件资源即表示您同意仅将其用于学习目的,若因违反此规定导致任何法律纠纷或损失,责任由您自行承担。
原创版权
本网站上的原创内容,包括但不限于文字作品、自行设计的图片、独家制作的音频视频等,其版权均归本网站所有。未经本网站书面授权,任何组织或个人不得擅自复制、转载、摘编、传播或以其他任何方式使用这些原创内容。如需使用,请提前与我们联系并获得书面许可,同时需在显著位置注明出处及作者信息。
转载与引用规范
若您需转载本网站文章,务必注明文章来源为 “[TomgZHE研习社],原文链接:[ https://blog.tomgzhe.com/index.php/2025/10/16/video-x265-nalu]”;对于有明确作者署名的文章,还需完整保留作者姓名。在引用本网站内容时,请确保内容准确无误,并遵循学术及行业的引用规范。
 微信扫一扫打赏
微信扫一扫打赏  支付宝扫一扫打赏
支付宝扫一扫打赏